Responsive Listening Head Generation
A Benchmark Dataset and Baseline
Abstract
We present a new listening head generation benchmark, for synthesizing responsive feedbacks of a listener (e.g., nod, smile) during a face-to-face conversation. As the indispensable complement to talking heads generation, listening head generation has seldomly been studied in literature. Automatically synthesizing listening behavior that actively responds to a talking head, is critical to applications such as digital human, virtual agents and social robots. In this work, we propose a novel dataset "ViCo", highlighting the listening head generation during a face-to-face conversation. A total number of 92 identities (67 speakers and 76 listeners) are involved in ViCo, featuring 483 clips in a paired "speaking-listening" pattern, where listeners show three listening styles based on their attitudes: positive, neutral, negative. Different from traditional speech-to-gesture or talking-head generation, listening head generation takes as input both the audio and visual signals from the speaker, and gives non-verbal feedbacks (e.g., head motions, facial expressions) in a real-time manner. Our dataset supports a wide range of applications such as human-to-human interaction, video-to-video translation, cross-modal understanding and generation. To encourage further research, we also release a listening head generation baseline, conditioning on different listening attitudes. Code & ViCo dataset: https://project.mhzhou.com/vico.
Dataset Video Samples
positive attitude
negative attitude
neutral attitude
Dataset Details
Our dataset can be accessed through OneDrive. In Conversational Head Generation Challenge, we use the subset of ViCo with newly collected talking head videos.
Guidelines
The dataset consists of three parts:videos/*.mp4: all videos without audio trackaudios/*.wav: all audios-
*.csv: return meta data about all videos/audiosName Type Description attitude str Attitude of video, possible values: [positive, negative, neutral] audio str Audio filename, can be located by /audios/{audio}.wavlistener str Listener video filename, can be located by /videos/{listener}.mp4speaker str Speaker video filename, can be located by /videos/{speaker}.mp4listener_id int ID of listener, value ranges in [0, 91]speaker_id int ID of speaker, value ranges in [0, 91]data_split str The data split of current record, possible values: [train, test, ood]
Generations
Compare Generations with Ground-Truth
Generate with different attitudes
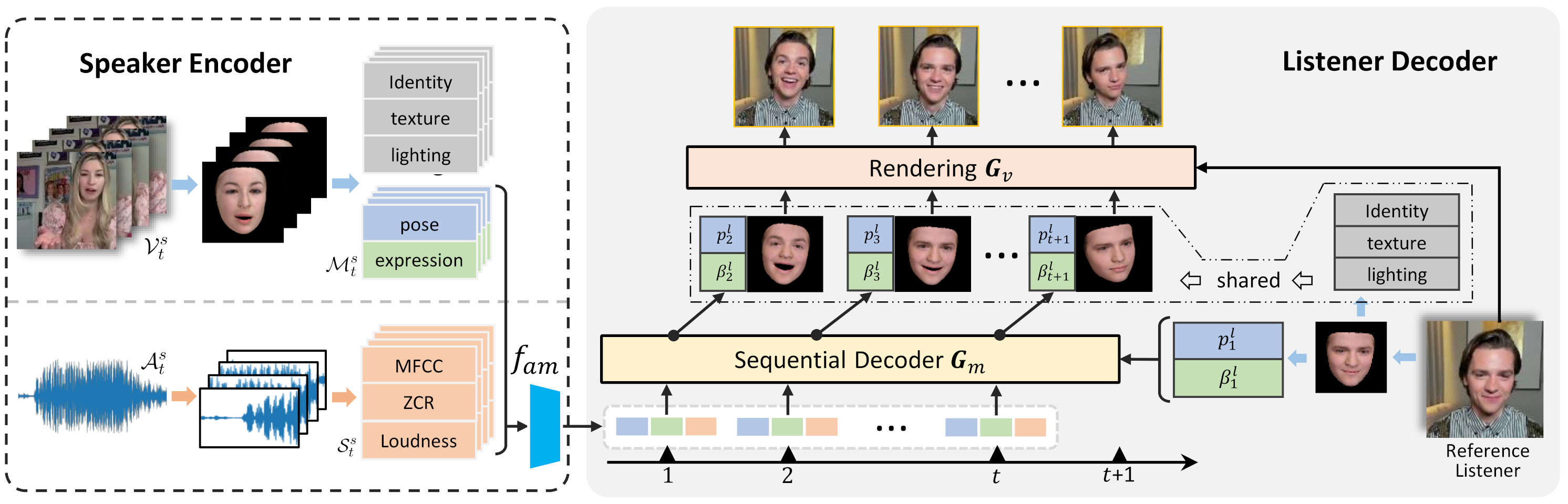
Method Details
Citation
If our dataset / code helps your research, please cite our paper.
@InProceedings{zhou2022responsive,
title={Responsive Listening Head Generation: A Benchmark Dataset and Baseline},
author={Zhou, Mohan and Bai, Yalong and Zhang, Wei and Yao, Ting and Zhao, Tiejun and Mei, Tao},
booktitle={Proceedings of the European conference on computer vision (ECCV)},
year={2022}
}
Ethical Use
The RLD dataset would be released only for research purposes under restricted licenses. The responsive listening patterns are identity-independent, which reduces the abuse of facial data. The only potential social harm is "fake content", while different from talking head synthesis, responsive listening can hardly harm the information fidelity.